


统计分析软件StatMate的样本量
统计分析软件StatMate的样本量
介绍
在示例的上下文中,样本大小的计算。我们将使用的示例是二十年前从事的项目,那时并没有真正对样本量进行正式分析,然后在下个示例中,我们将使用功效分来帮助理解我们实际获得的结果。
注意:使用StatMate,此示例强调样本量计算背后的逻辑,而不是使用StatMate的机制。
先介绍一下背景。血小板(血液中有助于凝结的小细胞)具有α2肾上腺素能受体。血液中的肾上腺素(肾上腺素)与这些受体结合,使血小板粘稠,因此它们聚集在一起,有助于血液凝结。高血压是一种复杂的疾病,但是有证据表明,肾上腺素能信号系统可能在高血压中异常。
我们对心脏,血管,肾脏和大脑感兴趣,但显然无法接受人体内的那些组织。相反,我们决对血小板上的α2-肾上腺素能受体进行计数,并比较有和没有高血压的人。
我们应该使用多少个科目?25年前,当我们进行这项研究时,我们选择了样本量。但是我们应该做个样本量分析。在接下来的几个屏幕中,我们将向您展示如何使用StatMate。
步骤1:选择分析
在步骤1中,通过两个问题来选择StatMate执行的分析类型:
你的目标是什么?对于此示例,我们要计算新研究的样本量。稍后,将通过个示例来确定完成的实验的功效。
您的实验设计是什么?在此事例中,我们计划使用未配对的T检验比较俩组的平均值。

步骤2:估算SD
在步骤2中,StatMate要求我们输入我们看到的标准偏差(SD)

如果您期望值之间分散很多(高SD),那么您将需要较大的样本量。另一方面,如果您期望之间的分散很小(低SD),则不用太多。除非您可以估计期望看到的分散量,否则根本无法估计的样本量。
对于本示例,我们使用来自研究血小板α2肾上腺素受体的数据,原因不同。这些研究表明,每篇血小板的平均受体数量约为250,标准片检查约为65。为什么这么高?这可能是生物学变异,受体技术的试验误差和血小板计数的试验误差的组合。使用先研究来获得SD直通常比使用先导研究。
StatMate接下来会要求您选择类别alpha。这是P值,低于该P值,您认为结果“具有统计意义”,因此拒绝零假设。
您应该根据产生I型错误的结果来设置a值(结果是,实际上治疗无效差异是由于随机变异而造成的差异具有统计学意义)。如果造成I类错误的后果严重,请将a设置为较小的值,则需要主题。如果类型I错误的后果很小,请将a设置为较高的值,这样您就可以减少主体的负担。
大多数研究人员始终将alpha设置为0.05(俩位),我们将执行相同的操作。注意:按钮“编辑功效和Ns...”使您可以修改下个屏幕上使用的功效和样本量列表,默认设置都很好,在此示例中,我们将保留默认设置。
步骤3 :查看样本大小和功效的权衡
一些程序会在此时间询问您的统计能力的效果大小。然后,程序将告诉您的样本量。这种方法的问题在于,您通常无法说出的功率或的效果大小。您想设计个具有很高功效的研究统计意义定义来检测很小的影响。但是,这样需要大量的科学研究。
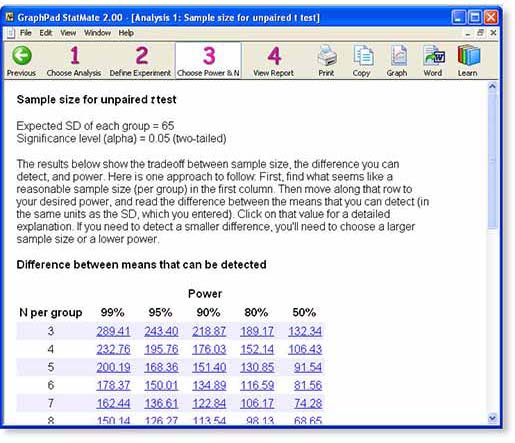
StatMate提供了个表格,该表格显示了样本大小,功效以及您将能够检测出的具有统计学意义的效应大小之间的权衡。
该表格提供了大量信息
表格中的每行代表您可以选择的潜在样本量。数字代表每组中的样本量。
每列代表不同的功效。研究的能力是这个问题的答案:如果均值之间的真实差等于列表值,那么在指定样本大小的实验中,P值小于0.05的可能性是多少?此示例,因此被视为“具有统计意义”。您可以通过在步骤2中单击“编辑功率和Ns...”来更改使用的功率列表。
由于此示例用于不成对的t检验,因此表中的值都是两组平均值之间的差,以与您在步骤2中输出的SD相同的单位表示。在此示例中,数据表示为数字血小板的受体数量。
现在困难的部分
您需要查看此表,并找到令人满意的样本大小,功效以及可以检测到的差异的组合。接下来,我们将概述三种方法A,B,C
方法A
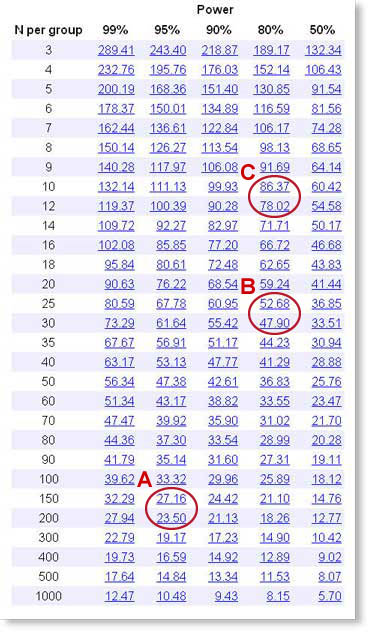
通过这种方法,我们计划研究,并有足够的时间和资金。
我们应该使用什么点源?我们选择了5%的传统显着性水平。如果俩组之间的平均受体数确实没有差异,那么,仍然有5%的几率会碰巧在俩组之间产生如此大的差异,我们将其称为统计学差异重大。我们还有5%的概率错过真正的差异。
我们正在寻找什么尺寸差异?尽管我们尚未对高血压患者进行研究,但我们研究发现,每张血小板的平均受体数量约为250个。假设我们要找到10%的差异,因此细胞25个受体的均值之间存在差异。
向下看95%功效栏,找到25附近的值。该值大约介于N=150和N=200之间,因此每组大约需要175个受试者。
方法B显示了可以证明较少主题的方法。
方法B
在这种方法中,我们样本量较少,并且愿意为此做出让步。
我们应该使用点源?使用80%的功率是很常规的。如果列表大小确实存在差异,则在进行研究时,我们有80%的机会获得“统计上显着”的结果(P<0.05),而有20%的机会错过了该大小的实际差异。
我们正在寻找什么尺寸差异?尽管我么尚未对高血压患者进行研究,但我们研究发现,每张血小板的平均受体数量约为250个。我们将关心多少差异?在方法A中,我们寻找10%的差异。相反,让我们看一下20%的差异,即细胞50个受体的均值之间的差异。
往下看80%功效栏,找到接近50的值。该值大约介于N = 25和N = 30之间,因此每组大约需要28个主题。
方法C
建设我们的预算允许进行每组11个主题的学习。,我们可以获得多少信息?这样研究值得吗?
通过少量研究,我们将不得不使用适度的功率。但是,右边的列具有50%的功效。即时我们假设的是真正的效果,也有50%的机会获得“具有统计意义的结果”。在这种情况下,进行实验有什么意义?我们想要的功率更多,但是知道如果没有大的样本量,我们将无法拥有巨大的功率。因此,让我们选择80%的功率,如果列表大小确实存在差异,则在进行研究时,我们有80%的机会获得“统计上显着”的结果(P<0.05),而遗漏了20%的机会真正的区别。
如果我们向下看80%功率列,则在N=11行中,我们发现可以检测到86.4的差异。我们已经知道,α2-肾上腺素能受体的平均数约为250,因此每组样本量为12的样本具有80%的功效来检测35%(86.4 / 250)的受体变化。
样本量分析帮助我们弄清楚了鉴于我们已经选择的样本量,我们学习什么。现在我们可以决定该实验是否值得进行。不同的人会对此做出不同的决定。但是有人会出结论,较小的差异可能在生物学上很重要,并且如果我们能检测到35%的巨大变化,有80%的功率,根本不值得进行实验。
三种方式哪种是正确的?
如果您指定的功能以及想要检测的效果大小,StatMate可以告诉您的主题数。
但通常,您不确定要获得什么功能,或者要检测出多大的效果。因此,您可以证明样本都是合理的。这取决于要找到的效果的大小,要确定要找到他们的功效以及错误地发现明显差异的医院(alpha)。这取决于您寻找差异的原因以及进行实验的成本。
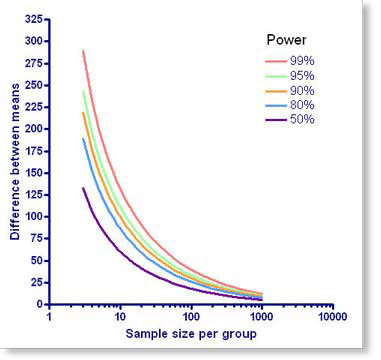
画出N与功率之间的关系
StatMate本身不会创建图。但是,如果您拥有GraphPad Prism版本4.01(Windows)或4.0b(Mac)或以上版本的副本,需单击“图形”按钮即可在prism中制作即时图形。每条曲线具有不同的功效,并显示了可以为组选择的样本大小(X)与随后将将厕位“显着”(Y)的差异之间的关系。
当您从左向右移动时,曲线会下降。这很有意义-如果您使用主题(收集的数据),那么您将能够可靠地检测出较小的差异。每条曲线具有不同的功效。如果选择的高功率,曲线将向右移动。这也是有道理的 - 如果您想要的功能(减少真正差异的机会),那么您将需要更多的主题。
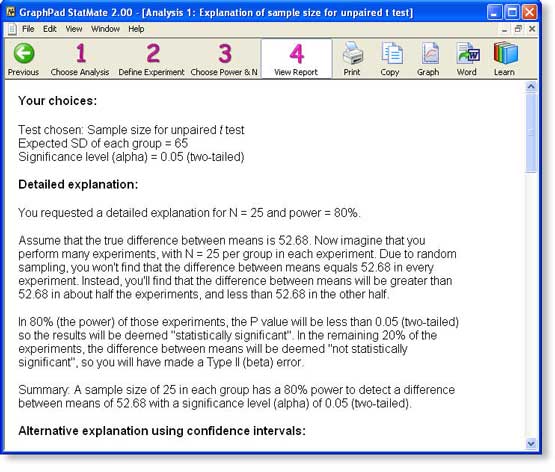
步骤4 : 查看StatMate的报告
我们将选择在方法B中选择的样本大小。在StatMate的步骤3中,值都是链接。我们单击80%功率列和N=25行(52.68)中的链接,StatMate会提供的报告。
下面的屏幕快照显示了报告四个部分的前两个部分:重申您的选择以及详细的解释。然后,该报告显示了权衡的整个表,并讨论了合适设计不相等样本量的研究是否有意义。
您可以将本示例的整个报告查看为PDF文件。您可以通过单击按钮(限Windows)或通过复制和粘贴将整个报告发送到Word。

-
2026-03-26
Origin 2026 SR1 服务更新包发布
Origin 2026 服务更新包1现已发布,适用于更新现有Origin或OriginPro 2026 SR0安装或全新安装。本次更新修正了智能填充、Excel公式、分组绘图批量操作及合并图形兼容性等多处问题,并解决了部分崩溃错误。安装后版本号将升级到10.3.0.197,用户可通过“帮助:关于Origin”确认更新完成。
查看详情 >
-
2026-04-13
GMS 10.9 中文版正式发布 — 新增 PFAS 运移模拟与地下水能量(GWE)模块
GMS 10.9 中文版现已发布。本次更新新增 MODFLOW-USG Transport 对 PFAS 运移模拟的支持、MODFLOW 6 地下水能量(GWE)模型、UGrid 多项改进以及 MODFLOW 6 界面优化等功能,为地下水数值模拟与地热储能分析提供更多工具支持。
查看详情 >
-
2026-03-10
GTAP数据库 V12已正式发布 - 附视频介绍
GTAP(Global Trade Analysis Project)是一个设立在美国普渡大学农业经济系的经济研究组织。该项目成立于1992年,旨在为贸易政策分析和可计算一般均衡(CGE)建模提供数据支持。全新版GTAP V12已于2026年2月正式发布,欢迎联系北京睿驰科技订购正版GTAP数据库。
查看详情 >

