


Stata 17中的可自定义表格,第三部分:经典表格1
在前两篇文章中,向您展示了如何使用新的和改进的table命令来创建表,以及如何使用collect命令来自定义和导出表。在这篇文章中,将向您展示如何使用这些工具来创建一个描述统计表,通常被称为”经典表1“。我们的目标是在下面的Microsoft Word文档中创建表格。
创建基本表
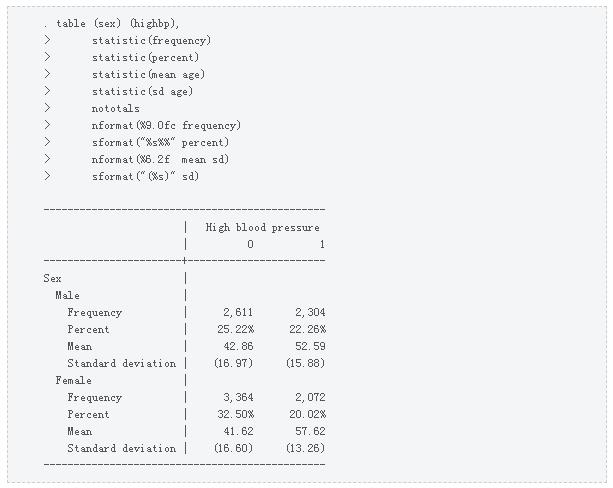
让我们先输入webuse nhanes2l打开NHANES数据集并使用table创建之前文章中的表。已经包含了从表中删除行总计的notobal选项。

回想一下那个表会自动创建一个集合,我们可以输入collect dime来查看我们集合中的维度。

维度结果是由table命令中的statistic()选项创建的。让偶我们输入collect label list result来查看维度result的级别和标签。

输出告诉我们结果有四个维度:fvfrequency、fvpercent、mean和sd。在默认情况下,这些级别在我们的表格中彼此堆叠,将它们并排放置,让我们使用collect recode创建两个名为column1和column2的新级别。然后,我们可以将fvfrequency和mean中的信息放在column1 中,将fvpercent和sd中的信息放在column2 中。

让我们输入collect label list result来查看我们维度result创建的新级别。

输出告诉我们,除了其他级别之外,维度结果现在还包括级别column1和column2.
接下来,我们可以使用collect布局来更改表格的布局。行维度仍然是highbp。我们可以通过将列维度指定为highbp#
result[column1 column2]来将column1和column2嵌套在highbp下。注意highbp和result[column1 column2]之间的#运算符。维度结果有六个级别,但我们只想包括级别column1和column2。因此,我们将要包含在括号中的级别括起来。

创建一个更大的表
现在我们有了表格的基本布局,让我们添加一些额外的变量。我们可以在statistic()选项中包含多个变量。例如,在先个statistic()选项中包含了年龄和bmi。年龄和bmi出现在我们的表中,然后是sex、race和hlthstat,然后是tcresult/tgresult和hdresult。行的顺序有Statustic()选项的顺序决定。已经包括了总的在这篇文章中再次选择减少表格的宽度,但删除了nottotal选项以在下面的Microsoft Word文档中创建表格。
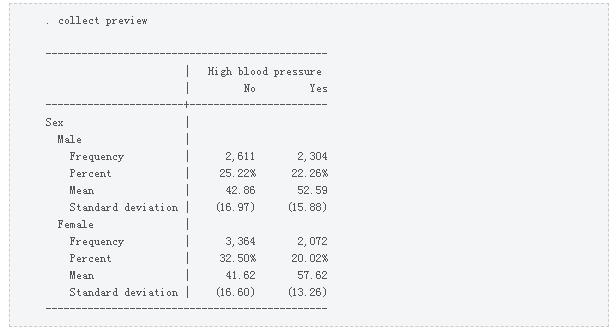
再次使用collect recode为维度result创建级别column1和column2。使用collect布局来更改我们表的布局。

自定义数字显示
现在可以自定义表格的样式。让我们从自定义数字的显示开始。在以前的文章中,我们使用格式化的数字nformat()和sformat()在我们的选项表命令。我们还可以将这些选项与collect样式单元格一起使用。我们可能对表格中的不同单元格引用不同的格式,并收集样式单元格使用维度和级别来引用表格中的单元格。
下面输出中的一行就是一个很好的例子。我们想格式化因子变量的频率。因此,我们要格式化表格中满足两个条件的单元格。一个条件是行维度var具有级别sex、race或hlthstat。第二个条件是列维度结果具有级别column1。我们只想格式化同时满足这两个条件的单元格,因此我们使用#运算符来指定这两个条件的交集。我们可以使用nformat(%6.0fc)来显示那些小数点右侧没有数字的单元格,并在千位位置包含一个逗号。
下面输出中的第二行格式化百分比。这些单元格中var的级别分别为sex、race或hlthstat,而result的级别为column2。我们可以使用nformat(%6.1f)来显示小数点右侧一位数的单元格,并使用sformat(“%s%%”)在数字后放置%。
sex、race或hlthstat。第二个条件是列维度结果具有级别column1。我们只想格式化同时满足这两个条件的单元格,因此我们使用#运算符来指定这两个条件的交集。我们可以使用nformat(%6.0fc)来显示那些小数点右侧没有数字的单元格,并在千位位置包含一个逗号。
之后我们可以输入collect preview来查看对表的更改。

自定义列标签
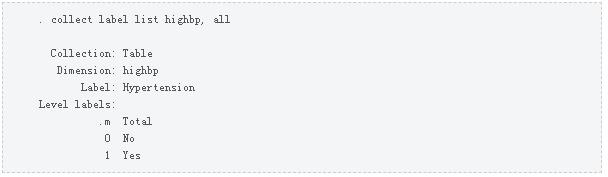
接下来,让我们使用在第二篇文章中学到的命令自定义表中的列标签。下面输出中的First line使用collect label dim将维度highbp的标签更改为“Hypertension”。下面输出中的第二行使用收集标签级别来标记级别0“No”和级别1“Yes”。
下面输出中的第三行使用收集样式标题来隐藏列标题中的维度结果级别。这将从列标题中删除column1和column2。
自定义行标签
接下来,让我们自定义表中的行标签。下面输出中的first line使用collect 样式行来更改几项内容。参数堆栈将级别的类别堆叠在彼此之上而不是并排堆叠。例如,男性和女性被放置在级别标签Sex之下。所述nobinder选项删除=以前显示每个级别和它的类别之间。而间隔选项添加不同的创建水平之间的空间统计()选项。
下面输出中的第二行使用收集样式单元格从表中删除垂直。回想一下上一篇文章,垂直是表格中first columny右侧的边框。选项border(right, pattern(nil))将线条图案更改为 nil。

将表格导出到Microsoft Word文档
我对表格的布局很满意,准备将其导出为Microsoft Word文档。在插入表格之前,让我们使用putdocx为我们的表格添加标题。默认情况下,Microsoft Word会拉伸我们的表格以适应文档的宽度。我们可以使用layout(autofitcontents)选项来保留表格的原始宽度。
之后我们可以使用putdocx collect将我们的表格导出到文档中。在下面的代码块中使用了红色字体来强调自定义和导出图形的行。
请注意,下面文档中的图表包括标有“总计”的列。删除了上面例子中的那些列,这样表格就不会超过这篇文章的默认宽度。我只是从table命令中删除了nototals选项,以将“总计”列添加到Microsoft Word文档中的表格中。


结论
在这篇文章中,我们使用了在上两篇文章中学到的工具。我们用表格与统计()选项来创建我们的基本表,然后用来收集标签修改维度和等级的标签采集方式行自定义标签,并采集方式的表格去除垂直线。我们使用了collect 样式putdocx和putdocx collect来自定义我们的表格将其导出Microsoft Word文档。
我们还在这篇文章中学习了如何使用一些新的收集命令。学习了如何使用collect 重新编码维度的级别,如何使用collect布局来更改表格的布局,以及如何使用collect样式单元格来格式化表格中的数字。

-
2025-11-28
年末科研大礼包-装备升级,即刻启航
即日起,面向高校、科研院所与企业科研团队,下单正版科研软件,满额即赠实用科研好物,助力科研工作!
查看详情 >
-
2023-12-06
Pipe Flow Expert 中文快速入门指南:精通管道设计与流体动力学
深入了解PipeFlowExpert中文快速入门指南,掌握管道设计和流体动力学的基础知识。本指南涵盖了绘图界面的使用技巧、单位转换(公制或英制)、储罐和流体源的应用,以及连接点或节点的设置。详细介绍流量需求的计算方法、管道流向的分析技巧,以及如何设计开放式和封闭式管道系统。学习如何有效预防管道回流,以及如何选择和使用管道图门、管件、控制阀和喷头。此外,本指南还提供泵型号的选择指导和负流量泵的使用方法,旨在帮助初学者和行业人员提高在管道系统设计和分析中的技能和效率。
查看详情 >
-
2023-09-06
REFPROP正版软件基本操作指南
这份REFPROP正版软件基本使用方法指南详细介绍了从启动软件到查询流体物性的步骤。您将了解如何选择流体、查询指定点的物性、查询饱和状态的物性以及创建物性图表。无论您是初学者还是专家,这个指南都将帮助您轻松掌握REFPROP软件的操作技巧。
查看详情 >

