


Stata 17 中的可自定义表格,第 5 部分:一个回归模型的表格
在上一篇文章中,向您展示了如何使用带有command()选项的新的和改进的table命令来创建统计测试表。在这篇文章中,想向您展示如何使用command()选项为单个回归模型创建表。我们的目标是在下面的 Microsoft Word 文档中创建表格。
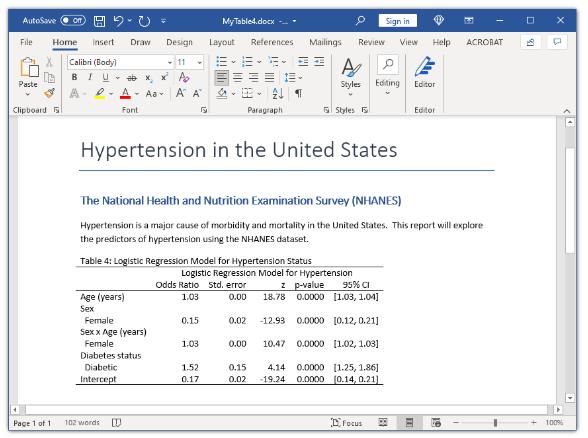
创建基本表
我们先输入webuse nhanes2l打开 NHANES 数据集,然后输入describe来检查一些变量。
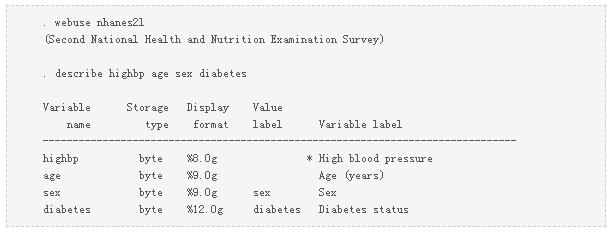
该数据集包括年龄、性别、高血压指标 ( highbp ) 和糖尿病指标 ( DM )。我们想为二元结果highbp拟合逻辑回归模型,并创建一个包含优势比、标准误差、z统计量、p 值和置信区间的表。请注意,我在下面的示例中使用了 Stata 的因子变量表示法来包括连续变量age的主要影响、分类变量sex和糖尿病的主要影响以及年龄和性别。
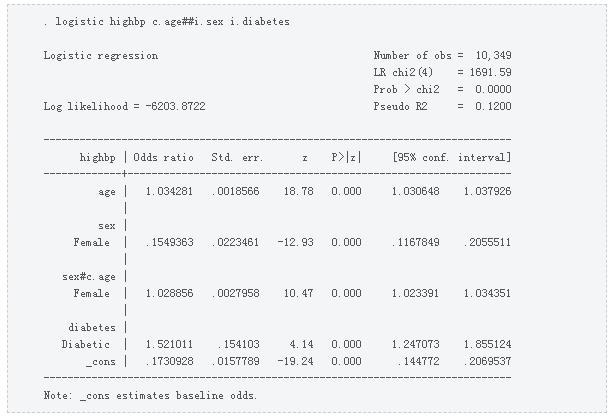
让我们先将逻辑回归命令放在table命令的command()选项中。没有行维度,列维度是command和result。

默认情况下,该表显示系数,实际上是优势比,因为我们使用了逻辑命令。
table自动创建了一个名为 Table 的集合,我们可以通过输入collect dims来查看维度。

维度结果有 43 个级别。让我们输入collect label list来查看级别及其标签。

我们对以_r开头的级别感兴趣,因此我省略了大部分输出。以_r开头的级别是系数表的内容。例如,级别_r_b包含系数(即优势比),级别_r_se包含标准误差,等等。请注意,置信区间存储在单个级别_r_ci 中,并且还分别存储在不同级别的上限和下限_r_lb和r_ub 中。
让我们通过将_r_b _r_se _r_ci 添加到我们的command()选项中,将优势比、标准误差和置信区间添加到我们的表中。稍后我们将添加z检验和p值。

接下来让我们自定义表格中数字的显示。我使用nformat()来显示比值比、标准误差和置信区间,小数点右侧有两位数字。我使用sformat()在置信区间周围放置方括号,并使用cidelimiter()在置信区间的下限和上限之间放置逗号。

优势比列标记为Coefficient,我们可以使用collect label levels将其更改为Odds Ratio。
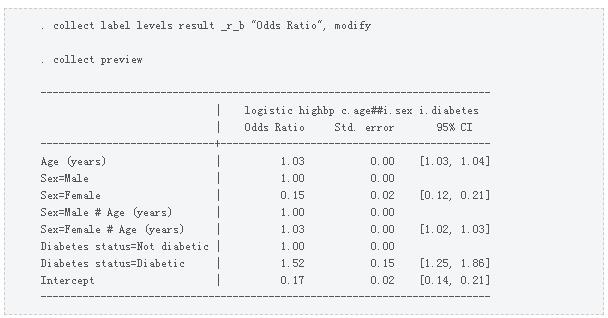
维度命令有一个级别,用我们的逻辑回归命令标记。我们还可以使用collect label levels修改其标签。

默认情况下,表格显示因子变量的基本水平,也称为“参照类别”或“参照组”。例如,标记为Sex=Male的行是因子变量i.sex的基础水平。男性类别用于优势比的分母。我们可以通过输入collect style showbase off来隐藏全部因子变量的基本水平,包括交互作用。

接下来让我们使用collect 样式行来自定义行标签。默认情况下,变量和类别与“绑定”字符并排显示。例如,Sex=Female显示变量Sex后跟 binder =后跟类别Female。选项堆栈显示变量名称一次,然后在变量名称下方显示每个类别。选项nobinder删除绑定字符=。交互使用#字符显示,我们可以使用delimiter(" x ")选项将交互分隔符更改为x。
我们在之前的帖子中删除了表格中的垂直线,我们可以在这里使用收集样式单元格来删除first column的右边框

我们可以在这里停下来,将我们的表格导出为 Microsoft Word 文档。但是您可能在表中包含z统计量和p值的列。我使用级别_r_z和_r_p在下面的代码块中添加了这些列
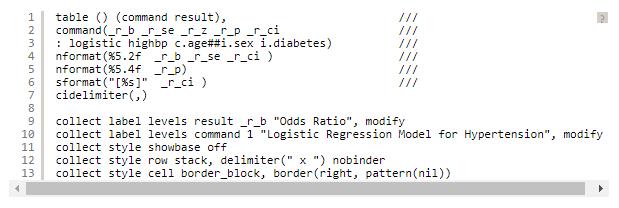

现在我们可以使用putdocx将表格导出到 Microsoft Word 文档中。

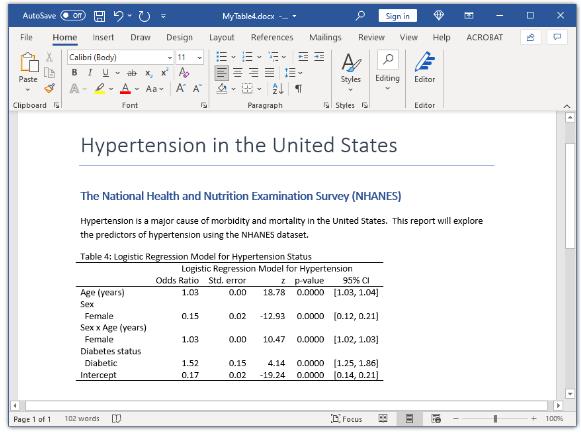
结论
在这篇文章中,我们学习了如何使用command()选项和table命令从逻辑回归模型创建表。对于别的回归模型,例如线性回归或概率回归,这些步骤几乎相同。
先指定列维度column和result。其次,选择列,例如_r_b和_r_ci,然后将回归命令放在command()选项中。然后根据需要自定义行和列标签以及数字的显示。
我将在下一篇文章中向您展示如何使用collect为多个回归模型创建表。

-
2026-03-26
Origin 2026 SR1 服务更新包发布
Origin 2026 服务更新包1现已发布,适用于更新现有Origin或OriginPro 2026 SR0安装或全新安装。本次更新修正了智能填充、Excel公式、分组绘图批量操作及合并图形兼容性等多处问题,并解决了部分崩溃错误。安装后版本号将升级到10.3.0.197,用户可通过“帮助:关于Origin”确认更新完成。
查看详情 >
-
2026-04-13
GMS 10.9 中文版正式发布 — 新增 PFAS 运移模拟与地下水能量(GWE)模块
GMS 10.9 中文版现已发布。本次更新新增 MODFLOW-USG Transport 对 PFAS 运移模拟的支持、MODFLOW 6 地下水能量(GWE)模型、UGrid 多项改进以及 MODFLOW 6 界面优化等功能,为地下水数值模拟与地热储能分析提供更多工具支持。
查看详情 >
-
2026-03-10
GTAP数据库 V12已正式发布 - 附视频介绍
GTAP(Global Trade Analysis Project)是一个设立在美国普渡大学农业经济系的经济研究组织。该项目成立于1992年,旨在为贸易政策分析和可计算一般均衡(CGE)建模提供数据支持。全新版GTAP V12已于2026年2月正式发布,欢迎联系北京睿驰科技订购正版GTAP数据库。
查看详情 >

